Abstract
Background
Handwriting synthesis plays a vital role in assistive technologies, data augmentation for robust authentication, and improving text recognition systems. The “one-shot” approach—generating handwriting from just a single style example—is particularly valuable for real-world applications where users can only provide minimal reference material.
Challenge
Capturing a writer’s unique style (e.g., stroke width, curvature, slant, and ink density) from a single image is extremely difficult. Existing GAN-based methods often produce unrealistic images and suffer from unstable training. Meanwhile, current diffusion models rely on fixed filters that overlook critical features like color and stroke density, or they require impractical “few-shot” references to achieve high quality. Furthermore, standard denoising processes often result in blurry or oversmoothed local details.
Key Contributions



-
CONSTANT Model: A novel one-shot handwriting generation framework based on denoising diffusion.
-
Style-Aware Quantization (SAQ): A module that represents handwriting as discrete visual tokens (“style concepts”), allowing the model to capture core stylistic traits while ignoring incidental noise.
-
Style Contrastive Enhancement ($L_{SCE}$): A training objective that refines the latent space to better distinguish between different writers.
-
Latent Patch Contrastive Enhancement ($L_{LatentPCE}$): A multi-scale patch-based objective that aligns generated and target features to sharpen local details and ensure visual consistency.
-
ViHTGen Dataset: The introduction of a new dataset specifically designed for Vietnamese handwriting generation.
Quantitative Results
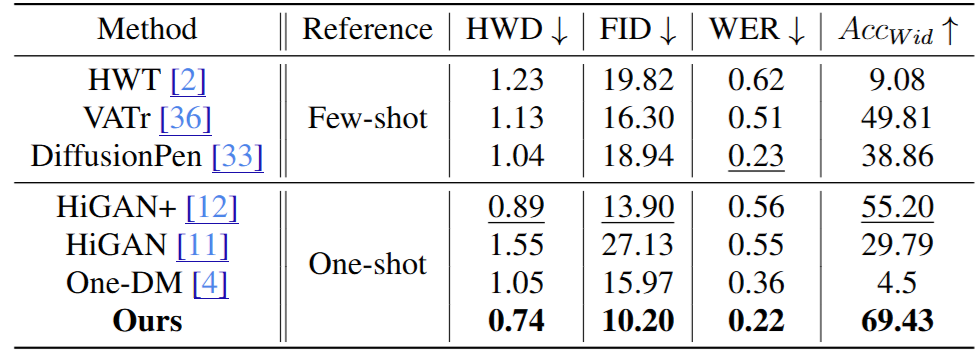
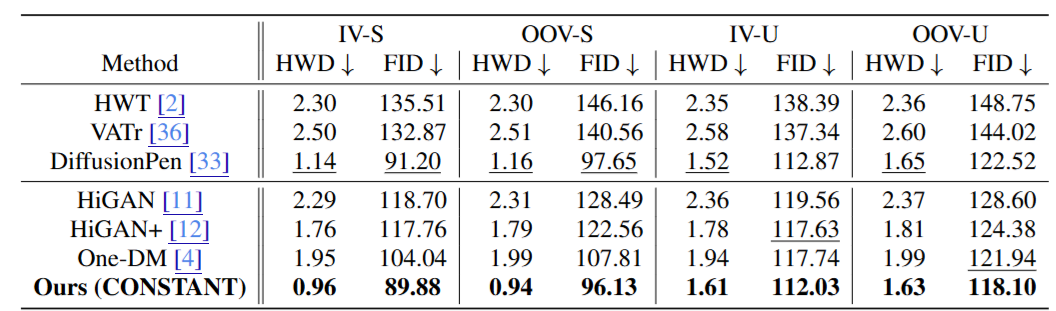


Key Results:
- SOTA on IAM (English): Achieved state-of-the-art results with a Handwriting Distance (HWD) of 0.74, FID of 10.20, and a Word Error Rate (WER) of 0.22, outperforming both one-shot and few-shot methods.
- Real-World Performance (IMGUR5K): Outperformed existing methods on complex real-world data with an HWD of 0.99 and FID of 11.48.
- Multilingual Adaptability: Demonstrated over 10% improvement in HWD scores for Chinese and Vietnamese scripts compared to previous state-of-the-art models like One-DM.
Qualitative Results
IAM
 *IMGUR5K
*IMGUR5K
 English-word-IIT
English-word-IIT

Key Findings:
- Precise Style Mimicking: The model accurately replicates complex stylistic features including ink color, character shapes, and slants.
- Detail and Readability: Unlike other methods that struggle with local consistency, CONSTANT generates sharp, legible text with high fidelity to the reference image.
- Robustness to Complexity: Successfully handles diverse backgrounds and difficult character shapes in various scripts, including those with complex stroke densities.
- Localized Attention: Interpretability analysis shows that the SAQ module focuses precisely on individual character strokes rather than producing diffuse, unfocused attention maps.
Citation